
Thanks in a large part to Zoom (of Knitnut.net), I have received 54 valid responses to my odds guessing experiment. As those who read the explanation already know, the point of the experiment was to assess how people assess the relative risks of a vague but more probable outcomes versus a concrete but less likely one. The vague result (1,000 deaths from flooding somewhere in the United States this year) was assigned to ‘heads.’ The precise result (1,000 deaths from Florida hurricane induced flooding) was assigned ‘tails.’
{kind=link}
The first result to note is the very wide disparity of answers. Responses for ‘heads’ ranged from 0.005% all the way up to 90%. Responses for ‘tails’ ran from 0% to 75%. Given that there has been no flood in American history that killed 1,000 people, it seems fair to say that most guesses are overestimates. That said, the point of the experiment was to judge the relative responses in the two cases, not the absolute accuracy of the responses. This scatterplot shows the complete set of responses for both questions.
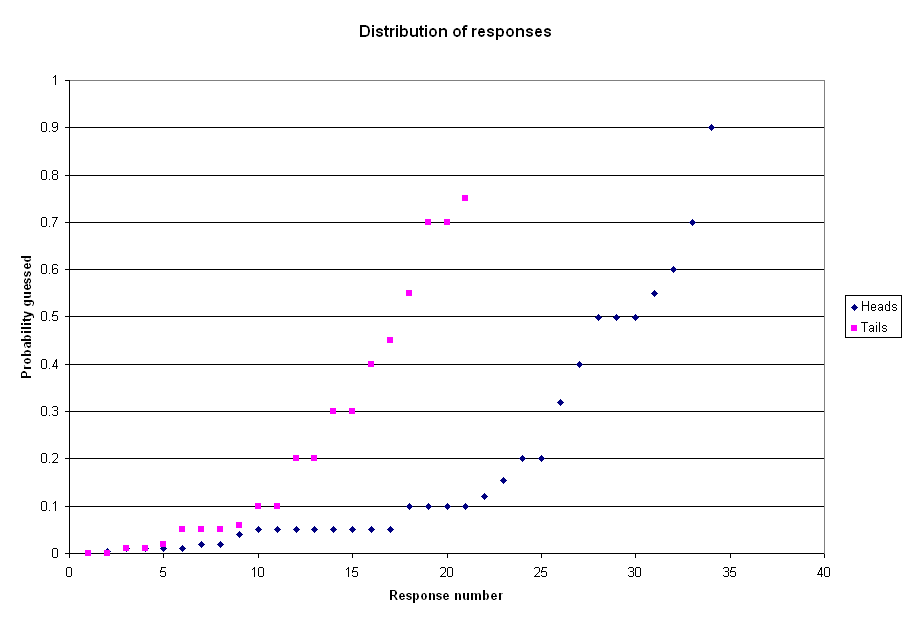{kind=link}
The mean probability estimate for ‘heads’ was 19.3%, while that for ‘tails’ was 23.8%. Because there were a large number of very high and very low guesses, it is probably better to look at descriptive statistics that aren’t influenced by outliers. This boxplot shows the mean, first and third quartile, maximum, and minimum results for each. To understand box plots, imagine that all the people who guessed are made to stand in a line, ranked from highest to lowest guess. Each of the numbers described previously (quartiles, etc) correspond to a position in the line. To find something like the median, you locate the person in the very middle of the line, then take their guess as your number. The advantage of doing this is that it prevents people who guessed very high from dragging the estimate up (as happens with the mean, or average), and doing the same with those who guessed very low.
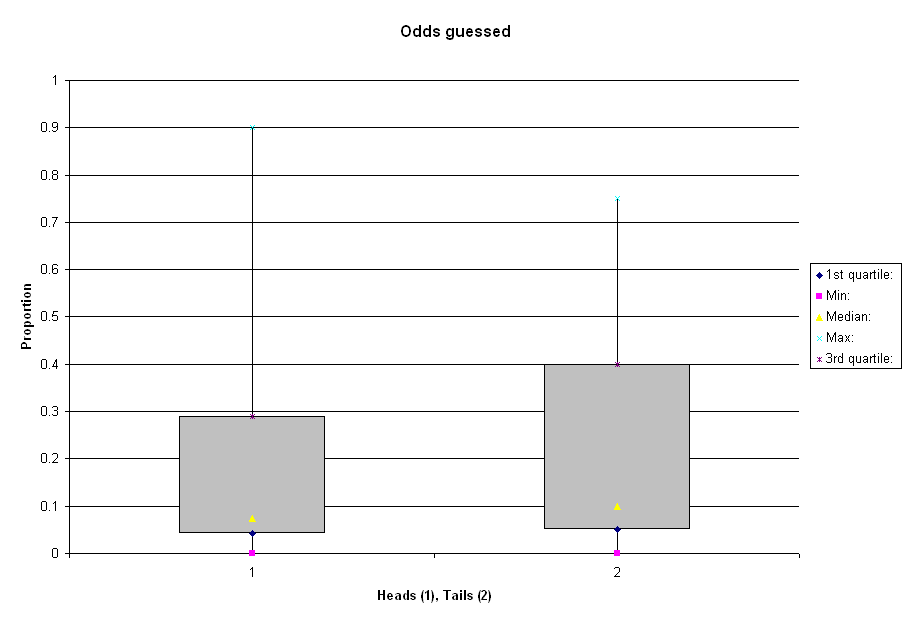{kind=link}
The yellow triangle is the median. For ‘heads’ the median was 7.5%, compared to 10% for tails. The gray boxes show the range of guesses made by half the sample. At the top is the guess made by the person 3/4 of the way up the line, and at the bottom is the one made by the person 3/4 of the way down the line. As you can see, the bottom half ot the range looks pretty similar. Half of people estimate that the risk of both the ‘heads’ and ‘tails’ outcome is between about 10% and about 0%. What differs most about the two distributions is the upper portion of the grey boxes. Whereas 75% of respondents thought the ‘heads’ option was less than 30% probable, that value was more like 40% for the ‘tails’ option.
A couple of problems exist with this experimental design. Among the 54 ‘coin tosses,’ 63% seem to have come up heads. While it is entirely possible that this is the result of fair throws, I think there is at least some chance that people just chose ‘randomly’ in their heads, in a way that favoured heads over tails. Another problem is that some people might have looked at the comments made by others before guessing, or may even have searched online for information about flooding probabilities.
In conclusion, I would say the experiment provides weak support for my hypothesis. It is undeniably the case that the ‘heads’ option is more likely than the ‘tails’ option, and yet both the mean and median probability assigned to ‘tails’ is higher. There are also significantly more people who assigned ‘tails’ a risk of over 10%.
Those wanting to do some tinkering of their own can download the data in an Excel spreadsheet.
[Update: 28 April 2008] There has been some debate about the point above about the slight heads-bias in the results. I am told that the odds of this outcome are one in 26.3. Whether random chance or a systemic bias better explains that, I will leave to the interpretation of readers. In any event, it only really matters if the ‘heads’ group and ‘tails’ group differed in terms of their natural perception of risk.
“Only where there is a substantial number of trials involved is the law of averages a useful description of prediction.” p.40 How To Lie With Statistics.
Since the 54 coin tosses you describe is a long way short of the 1000 approx needed for a 50-50 breakdown to be likely, it seems a little mean-spirited to infer that the respondents failed to coin toss.
Sarah,
I have been trying to calculate the probability, but all the equations I have used have led to nonsensical answers.
I will ask Mark how he came up with his 1 in 94 probability for the more preliminary odds.
Also, it isn’t necessarily too much of a problem if the heads-tails ratio isn’t 1:1 for whatever reason. It is only important that the difference between the two doesn’t represent any kind of non-random split between people who assess probabilities differently.
It also occurs to me that some of the coins concerned may not actually be ‘fair’, which would produce a biased result even with a very large sample if a number of respondents used the same coins. Do you know if the ‘fairness’ of Canadian coins have been tested? (See link.)
Further error may be introduced by the tossing process, specifically the orientation of the coin at the start: link